前回の記事では、DifyでX APIを使った「Xアカウント簡易診断ツール」の大まかな作り方をまとめました。
今回は3本目として実際に作る中で詰まったポイントとその解決法 を整理します。
API連携は、最初からすべてスムーズに進むことの方が少ないと思います。
特にDifyではノードのつなぎ方やレスポンスの受け取り方で一度つまずくとどこを見ればいいか分からなくなりやすいです。
そこで今回は、実際に止まったポイントを振り返りながら
- 何が起きていたのか
- どこを見れば原因が分かるのか
- どう直したのか
- 次からどう気をつければよいか
を順番にまとめます。
この記事で分かること
- HTTP Requestの
bodyが空でも、失敗とは限らないこと filesにJSONが入るケースの見方- Document Extractor を挟む理由
- ノード間で渡るデータ型を確認する大切さ
- 実装側の受け取りミスをどう直したか
- Difyで詰まったときの確認順序
最初にハマったのはHTTP Requestの body が空!!
X APIへのHTTP Request自体は成功していて、ステータスコードも 200 が返っていました。
それなのに、次のCodeノードで使いたかった body が空でした。
最初は、
- APIは成功している
- でも欲しいデータがない
- どこが悪いのか分からない
という状態になりやすいと思います。
実際に見えていたレスポンス
イメージとしてはこんな形でした
{
"status_code": 200,
"body": "",
"files": [
{
"filename": "xxxx.json",
"mime_type": "application/json"
}
]
}ここで大事なのはbody が空でもレスポンス自体が失敗しているとは限らないことです。
今回のケースでは、データが body に入っていなかっただけで、
実際のJSONは files 側に入っていました。
実際はfilesにJSONが入っていました
原因は、X APIから返ってきたレスポンスの扱い方にありました。
Difyではレスポンスヘッダーの内容によっては、HTTP Requestの結果を本文ではなくファイルとして扱うことがあります。
そのため、今回のように body は空でもfiles にJSONが入るケースがあります。
この挙動を知らないと、body だけ見て「取れていない」と思いやすいのですが、
実際には files を見にいく必要があります。
このときの見方
HTTP Requestノードの結果を確認するときは、まずこの3つを見ておくと分かりやすいです。
status_codebodyfiles
特に、
status_codeは成功bodyは空filesにJSONらしきものがある
というときは、files 側に本体が入っている可能性が高いです。
解決法は、Document Extractor を挟むこと
この問題に対して最終的にうまくいったのは
HTTP Request の直後に Document Extractor を挟む ことでした。
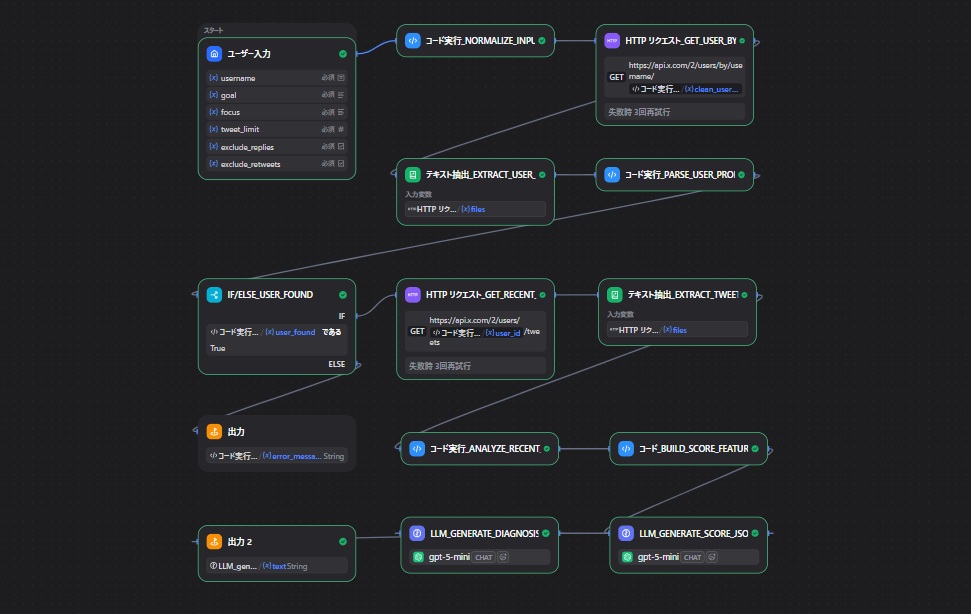
修正前の流れ
ユーザー情報を取得するプロフィールを整理する
この形だとCodeノードは body 前提で処理しようとしていたためうまくいきませんでした。
修正後の流れ
ユーザー情報を取得するユーザー情報を読み取るプロフィールを整理する
つまり、HTTP Request の直後に
ユーザー情報を読み取る = Document Extractor を挟む形に変えました。
なぜこれで解決したのか
Document Extractor を使うと、files に入っているJSONを読み取り、
後続のノードで使える text に変換できます。
そのため、
- HTTP Requestでファイルとして受け取る
- Document Extractorで中身を読む
- Codeノードで整形する
という流れにすると、かなり扱いやすくなります。
同じような状況に対応するためには
今回のように
bodyが空filesにJSONがある
というときは、Document Extractor を挟む という流れを思い出すとかなり分かりやすいです。
受け取る変数の型はしっかり確認する
受け取る値の型に合っているのか必ず確認する癖をつけましょう。
ここはDifyの仕様などではなく、私の失敗談 です。
最初は、Document Extractor から渡ってくる値を、文字列としてそのまま扱う前提で書いてしました。
raw = (text or "").strip()今回使っていたテキスト抽出ノードの出力は、Array[string] です。
つまり、1つの文字列ではなく、文字列の配列として返ってくる 前提でした。
この前提を見落としたまま文字列として扱ったため、次のようなエラーが出てしまい、「あれ?なんでだ?」となっていました。。。
AttributeError: 'list' object has no attribute 'strip'これはDifyの不具合ではなく、
こちらが出力型をきちんと確認せずstring前提で書いていたことが原因です。
配列も辞書も受け取れるようにした
実際にやった修正は、stringだけでなく list や dict も受け取れるように正規化する処理 をいれました。
例↓↓
def normalize_to_string(value) -> str:
import json
if value is None:
return ""
if isinstance(value, str):
return value.strip()
if isinstance(value, list):
parts = []
for item in value:
if isinstance(item, str):
parts.append(item)
else:
parts.append(json.dumps(item, ensure_ascii=False))
return "\n".join(parts).strip()
if isinstance(value, dict):
return json.dumps(value, ensure_ascii=False).strip()
return str(value).strip()そして、もともとの処理をこう変更しました。
raw = normalize_to_string(text)JSONは、そのまま json.loads() できるとは限らない
もう1つ意識したのは、受け取った文字列がそのまま完全なJSONとは限らない ことです。
今回は比較的素直な形で取れましたが、状況によっては
- code block
- 余計な改行
- 不要な文字
が混ざることもあります。
たとえば、こんな形です。
```json
{"data": {...}}
```この場合、そのまま json.loads() すると失敗します。
そこで、今回はこうしたコードも入れました。
if raw.startswith("```"):
raw = raw.strip("`")
raw = raw.replace("json\n", "", 1).strip()これを入れておくと、多少余計な装飾が混ざっていても吸収しやすくなります。
一番大事なのは各ノードの出力を見ること
今回いちばん大きかった学びは、
うまくいかないときほど、全体ではなく1ノードずつ確認すること でした。
最初は、
- APIが悪いのか
- コードが悪いのか
- Difyの設定が悪いのか
と一気に考えてしまいがちでした。
私が見た順番
今回のような構成なら、次の順で見ると整理しやすかったです。
ユーザー情報を取得するユーザー情報を読み取るプロフィールを整理する投稿一覧を取得する投稿一覧を読み取る投稿を分析する
それぞれで見るポイント
| ノード | 確認するもの |
|---|---|
ユーザー情報を取得する |
status_code、body、files |
ユーザー情報を読み取る |
text の中身 |
プロフィールを整理する |
user_found、error_message |
投稿一覧を取得する |
status_code、body、files |
投稿一覧を読み取る |
text の中身 |
投稿を分析する |
tweet_count_fetched、analysis_note |
このように、
ノードごとに「どの項目を見るか」を決めておく とかなり落ち着いて確認できます。
今回の経験から学んだこと
1. body が空でもHTTP Request失敗とは限らない
まずは files を確認する
2. Document Extractor はかなり重要
JSONがファイル扱いになったときは、間に挟むことで整理しやすくなる
3. ノード出力の型は必ず確認する
だろうではなく、必ず型を確認しないといけいないと感じました
まとめ
今回は、Dify×X APIで実際に詰まったポイントとその解決法をまとめました。
ポイントを整理すると次の通りです。
- HTTP Request が成功していても、
bodyが空のことがある - その場合、
filesにJSONが入っていることがある - そういうときは Document Extractor を挟むと整理しやすい
- その後は、ノード間で渡る値の型を確認することが大切
- うまくいかないときは1ノードずつ出力を見るのがいちばん早い
このあたりは、実際に手を動かしてみないと分かりにくい部分でもあるので、
同じようにDifyでAPI連携に挑戦している方の参考になればうれしいです。
次回は、このシリーズの最後として、
- 完成したツールで何ができるのか
- 商品としてどう見せられるのか
- 今後どこまで拡張できるのか
を整理していきます。
もし、
- DifyでAPI連携ツールを作ってみたい
- 自社向けに診断ツールや業務自動化を考えている
- こういう仕組みを自分でも作れるか相談したい
という方がいれば、無料相談・お問い合わせからお気軽にご連絡ください。
小さなところからでも、一緒に整理していければと思います。
コメント