前回は、DifyとGASを使って、指定したXアカウントの投稿を自動収集し、スプレッドシートに保存する仕組みの全体像を整理しました。
今回はその続きとして、Dify側でどのようにワークフローを組み、X投稿の取得と整形を行ったのかをまとめます。
特に今回は、単純にHTTP Requestをつなぐだけでは進まなかった部分も含めて、Difyで詰まりやすいポイントと対処方法もあわせて紹介します。
この記事でわかること
- GASから監視対象アカウント一覧を取得する部分
- X APIで各アカウントの投稿を取得する部分
- 投稿データを保存しやすい形に整える部分
- Dify特有の詰まりやすい仕様と対処方法
この記事ではDify側の構成と処理の流れについて紹介します。
スプレッドシート保存や重複除外を受け持つGAS側は次の記事で紹介させていただきます。
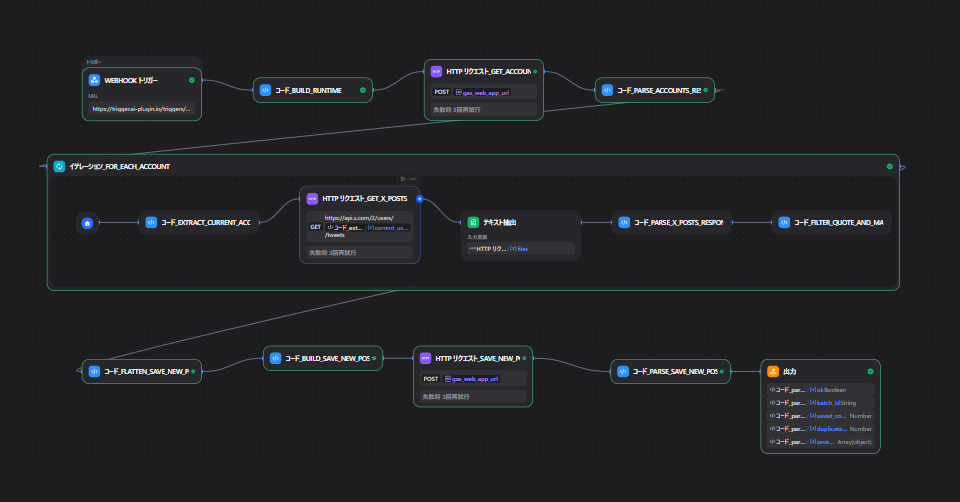
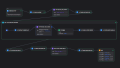
Difyワークフロー全体像
今回のDifyワークフローは、次の流れで組んでいます。
- Webhookでワークフローを開始する
- 実行時に使う値をCodeノードで整える
- GASから監視対象アカウント一覧を取得する
- 各アカウントをIterationで順番に処理する
- X APIから投稿を取得する
- 必要な項目だけを取り出して整形する
- 全アカウント分をまとめる
- 保存用のJSONを組み立ててGASへ送る
ワークフロー構成は、概ね次のようになります。
Webhook
→ コード_build_runtime
→ HTTP リクエスト_get_accounts_from_gas
→ コード_parse_accounts_response
→ Iteration_for_each_account
→ コード_extract_current_account
→ HTTP リクエスト_get_x_posts
→ Document Extractor
→ コード_parse_x_posts_response
→ コード_filter_quote_and_map
→ コード_flatten_save_new_posts_to_gas
→ コード_build_save_new_posts_payload
→ HTTP リクエスト_save_new_posts_to_gas
→ コード_parse_save_new_posts_response
→ Output役割ごとのノード構成
| 役割 | ノード | 内容 |
|---|---|---|
| 初期設定 | Webhook / build_runtime | 実行開始と共通変数の整形 |
| 対象取得 | get_accounts_from_gas / parse_accounts_response | 監視対象アカウント一覧を取得 |
| 投稿取得 | Iteration / get_x_posts | アカウントごとにX APIから投稿取得 |
| 投稿整形 | Document Extractor / parse_x_posts_response / filter_quote_and_map | 必要な項目だけに整形し、引用投稿を除外 |
| 保存準備 | flatten_save_new_posts_to_gas / build_save_new_posts_payload | 全件をまとめて保存用JSONを作成 |
| 保存実行 | save_new_posts_to_gas / parse_save_new_posts_response | GASへ渡して保存結果を返す |
初期設定とアカウント一覧の取得
Webhookで開始する理由
Webhook Triggerを起点にしてDify上でのテスト実行だけでなく、外部からの起動もできる形にしています。
たとえば、将来的に次のような広げ方がしやすくなります。
- 定期実行の入口にする
- 別ツールや外部処理から起動する
- テスト用と本番用の入口を分ける
build_runtime で共通変数を整える
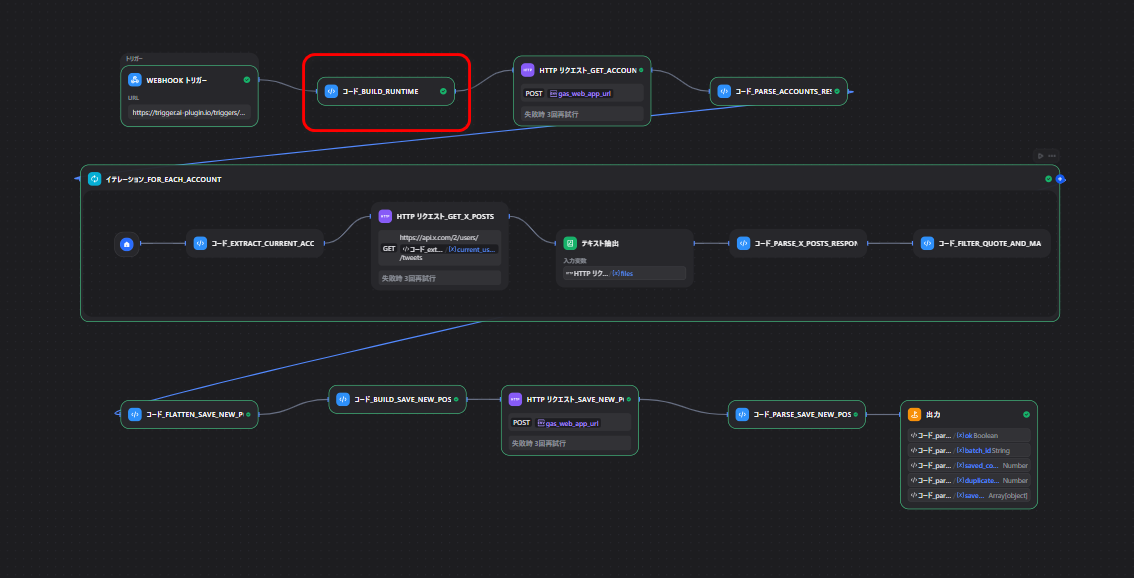
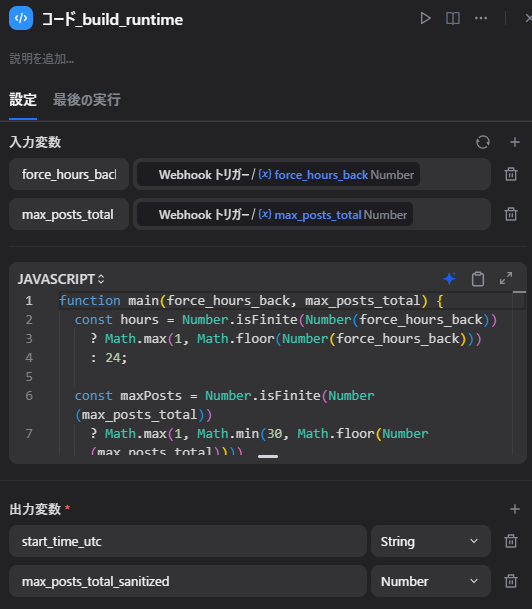
最初にCodeノードで、取得件数などの共通値を整えています。
たとえば、最大取得件数のような値を後続で使いやすい形にしています。
function main() {
return {
max_posts_total_sanitized: 30
};
}最初に値を整えておくと、後続のノードで同じ値を何度も組み直さずに済みます。
GASから監視対象アカウントを取得する
監視対象アカウントはDify側に直接書かず、スプレッドシートで管理しています。
そのため、DifyからはまずGASを呼び出して一覧を受け取ります。
この形にしておくと、対象アカウントの追加や削除があってもスプレッドシートの更新するだけで対応できます。
アカウントごとの投稿取得
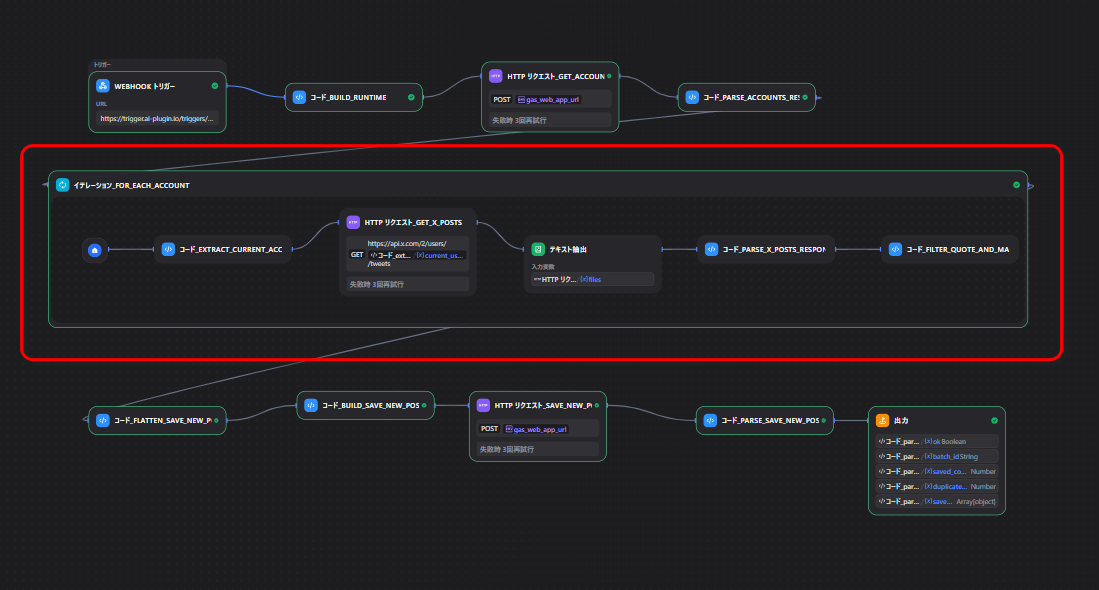
Iterationで複数アカウントを順番に処理する
アカウント一覧を受け取ったら、Iterationノードで1件ずつ処理します。
処理の流れはシンプルで、各アカウントごとに次を行います。
- 現在処理中のアカウント情報を取り出す
- X APIにリクエストを送る
- レスポンスを整形する
- 保存しやすい形式へ変換する
X APIの取得条件
今回は各アカウントの投稿を取得するために、ユーザーIDベースのタイムライン取得を使いました。
主な条件は次のとおりです。
- 対象は指定アカウントの投稿
- 返信とリポストは除外
- 作成日時と referenced_tweets を取得
引用投稿については、取得後に後段で除外しています。
投稿データの整形
HTTPレスポンスをそのまま読めないケース
今回、Difyで詰まりやすかったポイントの1つがここです。
X APIのレスポンスはJSONですが、Dify上では単純なテキスト本文として扱われず、filesとして認識されるケースがありました。
この場合、HTTP Requestノードの出力は次のような状態になります。
bodyは空filesにJSONファイル情報が入る
Document Extractor でbodyの空を解決
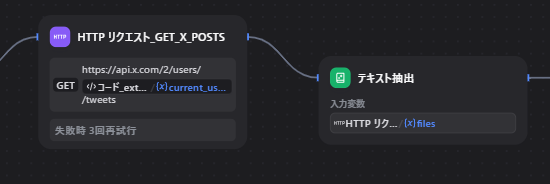
HTTP Requestの直後に Document Extractor を入れ、files を読み出して文字列化することで解決できます。
流れとしては次のようになります。
HTTP リクエスト_get_x_posts
→ Document Extractor
→ コード_parse_x_posts_responseこの構成にすると、Document Extractor の text にJSON文字列が入り、Codeノードで安全にパースしやすくなります。
必要な項目だけを取り出す
投稿取得後は、保存に必要な情報だけを残すようにしています。
今回使っている主な項目は次のとおりです。
idtextcreated_atreferenced_tweets
整形用のCodeノードは次のようになります。
function main({ text }) {
const emptyResult = {
posts: [],
posts_count: 0
};
const rawText = Array.isArray(text)
? String(text[0] || "").trim()
: String(text || "").trim();
if (!rawText) {
return emptyResult;
}
let parsed;
try {
parsed = JSON.parse(rawText);
} catch (error) {
return emptyResult;
}
const rawPosts = Array.isArray(parsed.data) ? parsed.data : [];
const posts = rawPosts
.map(item => ({
id: String((item || {}).id || "").trim(),
text: String((item || {}).text || "").trim(),
created_at: String((item || {}).created_at || "").trim(),
referenced_tweets: Array.isArray((item || {}).referenced_tweets)
? item.referenced_tweets
: []
}))
.filter(item => item.id !== "");
return {
posts,
posts_count: posts.length
};
}引用投稿を除外して保存用の形にする
取得した投稿をそのまま保存するのではなく、今回は引用投稿を除外し保存用に必要なURLなどを作っています。
function main({ x_posts, username, user_id }) {
const posts = Array.isArray(x_posts) ? x_posts : [];
const safeUsername = String(username || "").trim();
const safeUserId = String(user_id || "").trim();
const candidate_posts = [];
let quote_skipped_count = 0;
for (const post of posts) {
const refs = Array.isArray(post.referenced_tweets) ? post.referenced_tweets : [];
const isQuoted = refs.some(ref => String((ref || {}).type || "").trim() === "quoted");
if (isQuoted) {
quote_skipped_count += 1;
continue;
}
const postId = String((post || {}).id || "").trim();
if (!postId) {
continue;
}
candidate_posts.push({
post_id: postId,
username: safeUsername,
user_id: safeUserId,
post_url: safeUsername ? `https://x.com/${safeUsername}/status/${postId}` : "",
created_at: String((post || {}).created_at || "").trim()
});
}
return {
candidate_posts,
quote_skipped_count
};
}全アカウント分の集約と保存用データの作成
Iteration後の出力をそのまま使わない理由
Iterationの後は、期待していた形の配列にならないことがあります。
そのため実際の出力JSONを確認しながら、後続で扱いやすい形に整える必要がありました。
最終的に保存対象の投稿一覧を1つにまとめるため、専用のCodeノードで flatten しています。
function main({ iteration_posts, max_posts_total_sanitized }) {
const input = Array.isArray(iteration_posts) ? iteration_posts : [];
const flat = [];
for (const item of input) {
if (!item) continue;
if (Array.isArray(item)) {
flat.push(...item);
continue;
}
if (typeof item === "object") {
flat.push(item);
}
}
const uniqueMap = new Map();
for (const item of flat) {
const postId = String((item || {}).post_id || "").trim();
if (!postId) continue;
if (!uniqueMap.has(postId)) {
uniqueMap.set(postId, item);
}
}
const all = Array.from(uniqueMap.values()).sort((a, b) => {
const at = new Date((a || {}).created_at || 0).getTime();
const bt = new Date((b || {}).created_at || 0).getTime();
return bt - at;
});
const limit = Number.isFinite(Number(max_posts_total_sanitized))
? Math.max(1, Math.min(30, Math.floor(Number(max_posts_total_sanitized))))
: 30;
return {
all_candidates: all.slice(0, limit),
quote_skipped_count_total: 0
};
}保存用のJSONをCodeノードで作る理由
もう1つ詰まりやすかったのが、配列やオブジェクトをHTTP Requestへそのまま渡した時の崩れ方です。
Difyでは配列やオブジェクトをHTTP RequestのJSON bodyに直接差し込むと、送信先で想定どおりに受け取れないことがあります。
そのため今回はHTTP Requestの前にCodeノードを挟み、request_body_json を組み立てています。
function main({ all_candidates, max_posts_total_sanitized, gas_shared_secret }) {
const candidates = Array.isArray(all_candidates) ? all_candidates : [];
return {
request_body_json: JSON.stringify({
secret: String(gas_shared_secret || "").trim(),
action: "save_new_posts",
max_posts_total: Number(max_posts_total_sanitized || 30),
candidates: candidates
})
};
}そしてHTTP Request側では raw body としてそのまま送信しています。
この形にしておくと配列やオブジェクトの形が崩れにくくGAS側でも扱いやすくなります。
Difyで詰まりやすかった点と整理しておきたいこと
レスポンスの見た目と実データが一致しないことがある
DifyではUI上で見えているイメージと、実際の入力・出力データの形が一致しないことがあります。
JSONレスポンスのつもりで扱っていたものが files になっていたりなどです。
そのため、詰まったときはまず次を確認する方が整理しやすいです。
- 現在のノードの入力JSON
- 1つ前のノードの出力JSON
- 値が単体なのか配列なのか
- ノード全体を渡しているのか、出力値を渡しているのか
Codeノードの引数の受け方に注意が必要だった
Codeノードでは、複数入力があるときに function main(a, b) のように受けるより、function main({ a, b }) の形で受けた方が合う場面がありました。
この違いで値は入っているのに空扱いになることもありました。
空の出力が出たときは、入力JSONと関数の受け方を見直す必要があります。
配列やオブジェクトは HTTP 送信前に明示的に整える方が安定しやすい
複数投稿をまとめて保存する場合、配列データをそのままHTTP Requestへ渡すより、Codeノードで一度 JSON.stringify(...) してから送る方が安定しやすいです。
このあたりは「どの方法が絶対に正しい」というより、送信先で空になる、型がズレる、崩れるといった症状が出たときに見直したいポイントです。
この記事でできるようになったこと
記事の内容の作業をここまでやると、下記のことができるようになっています。
- 監視対象アカウント一覧の取得
- 各アカウントのX投稿取得
- 引用投稿の除外
- 保存用データの整形
- GASへ渡すためのJSON組み立て
つまり、Dify側では「集める」「整える」「保存に渡せる形にする」ところまで進んでいます。
まとめ
この記事では、Dify側でX投稿取得ツールをどう組んだのかを紹介してきました。
X APIの呼び出しそのものよりも、Dify上でデータをどう受け取り、どう整え、どう次のノードへ渡すかが特に重要だと感じました。
files扱いになるレスポンス、Iteration後の出力、配列を含むHTTP送信は、事前に知っておくと組みやすくなる部分でした。
次の記事では、GAS側で受け取ったデータをどう保存し、どう重複除外しスプレッドシート上でどう管理するのかを紹介しています。
- 競合アカウントのポストを保存したい
- SNS運用の業務を効率化したい
- 自社の運用に合う形で補助の仕組みを考えたい
という方がいれば、無料相談・お問い合わせからお気軽にご連絡ください。
今の運用に合わせて、どこまで自動化するのがちょうど良いか、一緒に整理できればと思います。
コメント