前回の記事では、Difyで作った「Xアカウント簡易診断ツール」の全体像を紹介しました。
今回は2本目として実際にDifyでどう組んだのかをできるだけ分かりやすくまとめます。
この記事では、
- どんなノード構成にしたのか
- X APIで何を取得したのか
- Codeノードでどんな処理をしているのか
- LLMに何を渡して診断させているのか
を順番に紹介していきます。
前提として今回は最小構成で動くMVPを意識しています。
最初から多機能にせず、まずは「アカウントを診断できるところまで」を目標にしています。
この記事で分かること
- Xアカウント簡易診断ツールの全体構成
- Difyで使ったノード一覧
- 各ノードの役割
- Codeノードのコード全文
- LLMプロンプトの考え方
- 最小構成で作るときにどこまでやれば十分か
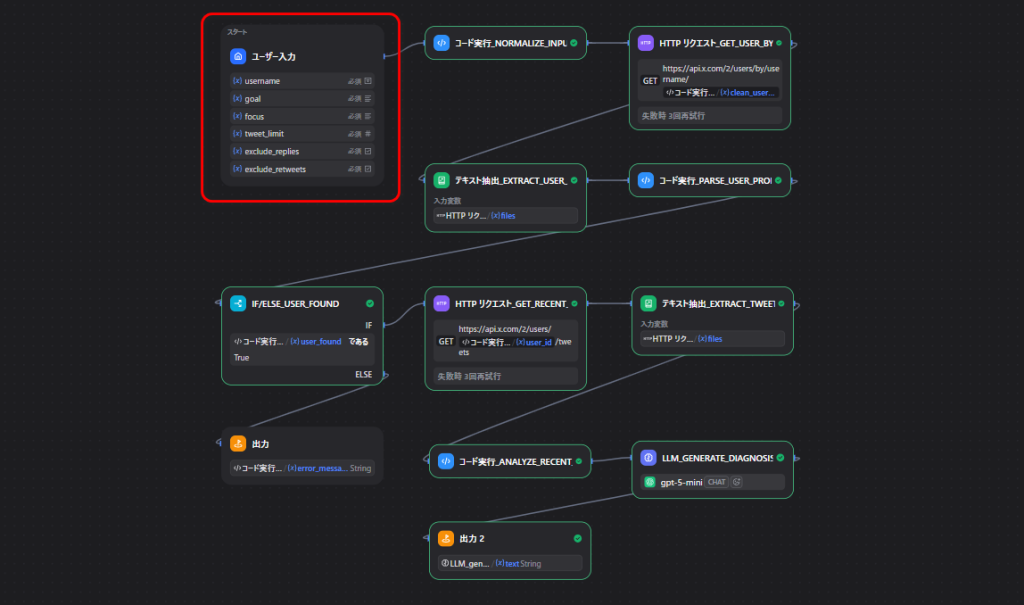
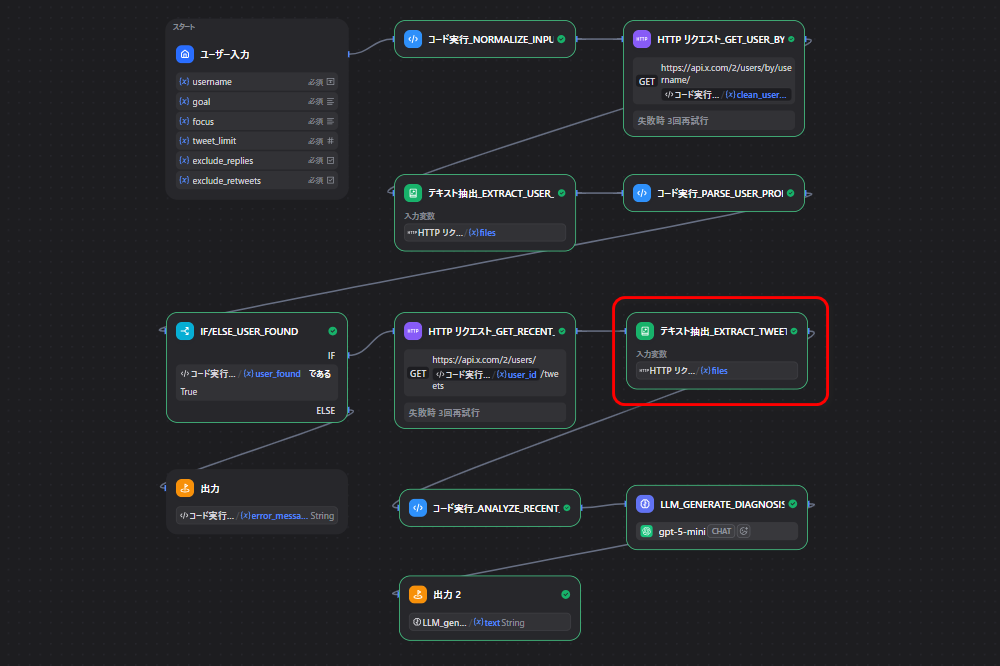
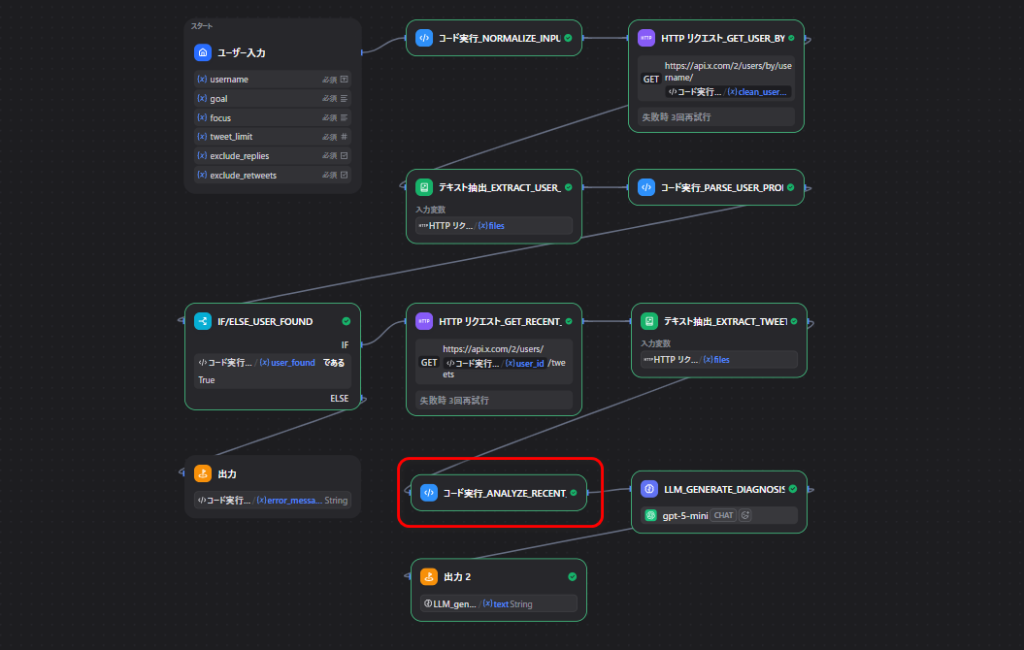
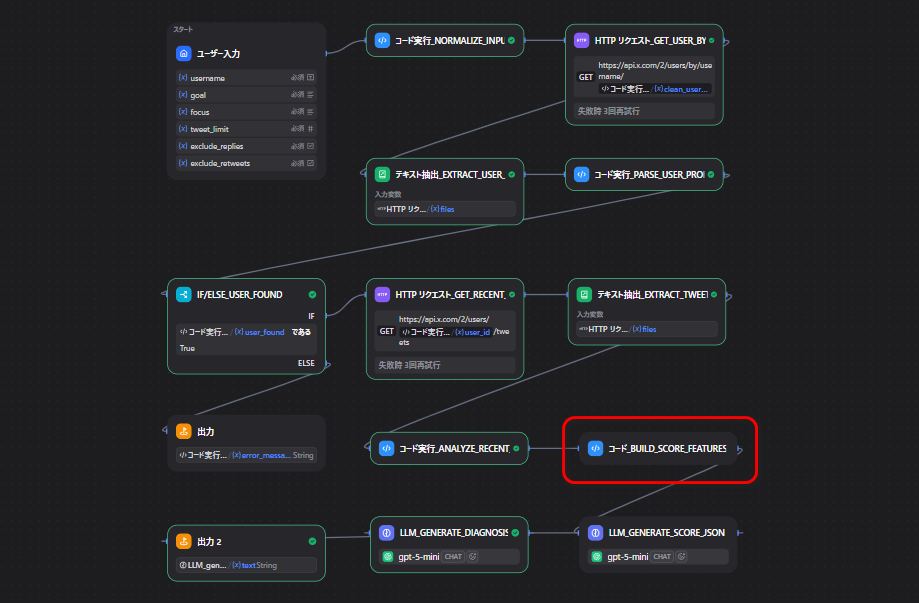
今回作るツールの全体像
このツールはXのユーザー名を入力するとプロフィールと直近投稿を取得しAIで診断レポートを返す仕組みです。
大きな流れは次の通りです。
- 入力値を整える
- X APIでユーザー情報を取得する
- X APIで直近投稿を取得する
- 取得したデータを整理する
- スコア用の材料を作る
- AIで診断レポートを作る
先に準備しておくもの
実際にDifyで作り始める前に、先にいくつか準備しておくものがあります。
この記事ではX Developer側の細かい登録手順そのものまでは扱いませんが、
Difyでこのツールを動かすために何を準備すればいいか が分かるように整理しておきます。
今回はX APIを使うのでノード構成を作る前に次の3つを用意しておくと進めやすいです。
1. X APIを使うための設定
今回のツールでは、Xのユーザー情報や直近投稿を取得するために、X APIを使います。
まずはX Developer側でAPIを使える状態にして、Bearer Token を取得しておく必要があります。
今回のツールで使う主なAPIは次の2つです。
- ユーザー情報の取得
- 直近投稿の取得
最初から検索系や競合比較まで入れなくても簡易診断ツールとしては十分形になります。
2. APIキーはコードに直接書かない
初心者の方が最初に迷いやすいのがここだと思います。
理由は次の通りです。
- あとで見返したときに管理しにくい
- コードを共有するときに消し忘れやすい
- うっかり公開してしまうリスクがある
そのため、今回はDify側で環境変数として認証情報を管理して使う形にします。
今回使う変数名は分かりやすく次のようにしておくのがおすすめです。
3. HTTP Requestノードではこう使う
今回のHTTP Requestノードでは次のように設定します。
認証APIキー: Bearer {{X_BEARER_TOKEN}}
Content-Type: application/json少し難しく見えるかもしれませんが、やっていることはシンプルです。
- APIキーはコードの中に書かない
- Dify側で安全に持っておく
- 必要なノードで呼び出す
この形にしておくとあとで修正するときもかなり楽になります。
4. 今回の事前準備まとめ
| 準備するもの | 内容 |
|---|---|
| X Developer設定 | X APIを使える状態にする |
| Bearer Token | API認証に使う |
| Difyのアプリ | Workflowアプリを作成する |
| 認証情報の管理 | X_BEARER_TOKEN として扱う |
ここまでできれば、次から実際にノードを組み始められます。
今回使ったノード一覧
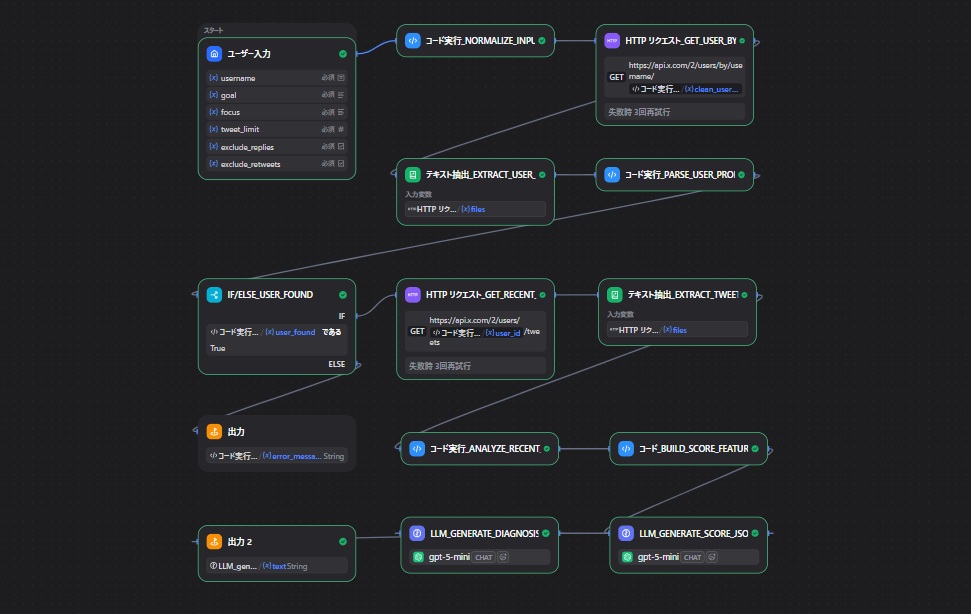
| ノード名 | 種類 | 役割 |
|---|---|---|
開始 |
Start | 入力を受け取る |
入力を整える |
Code | ユーザー名や条件を整える |
ユーザー情報を取得する |
HTTP Request | X APIでプロフィール情報を取得する |
ユーザー情報を読み取る |
Document Extractor | JSONファイルの中身を文字として読む |
プロフィールを整理する |
Code | ユーザー情報を扱いやすい形にする |
ユーザーが見つかったか確認する |
IF | エラー分岐をする |
投稿一覧を取得する |
HTTP Request | X APIで直近投稿を取得する |
投稿一覧を読み取る |
Document Extractor | 投稿JSONを文字として読む |
投稿を分析する |
Code | 投稿の平均値や上位投稿を整理する |
診断用データを整える |
Code | スコア用の特徴量を作る |
スコアを作る |
LLM | 100点満点のスコアJSONを作る |
診断レポートを作る |
LLM | 改善点や投稿案を含むレポートを作る |
終了 |
End | 最終結果を返す |
まず用意した入力項目
開始ノードでは、次の値を受け取るようにしました。
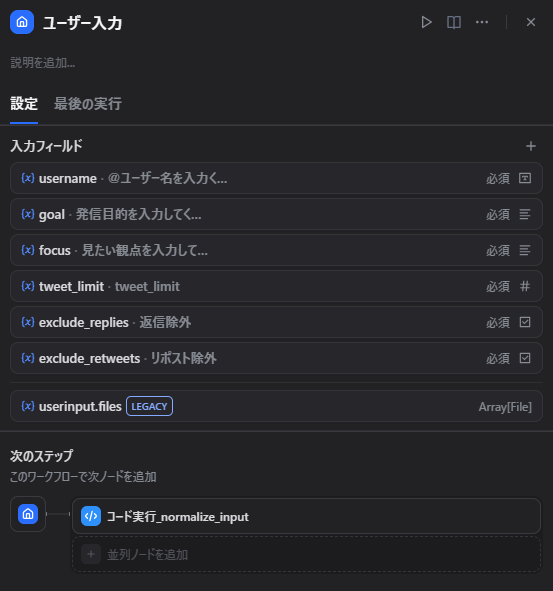
| 入力項目 | 型 | 例 | 説明 |
|---|---|---|---|
username |
文字列 | example_user |
Xのユーザー名 |
goal |
文字列 | 認知拡大 |
発信目的 |
focus |
文字列 | 投稿改善 |
見たい観点 |
tweet_limit |
数値 | 10 |
取得投稿数 |
exclude_replies |
真偽値 | true |
返信を除外するか |
exclude_retweets |
真偽値 | true |
リポストを除外するか |
最初は tweet_limit = 10 くらいで十分です。
むしろ最初から多く取りすぎない方がAPIコストも抑えやすく分析もシンプルになります。
ノード1: 入力を整える
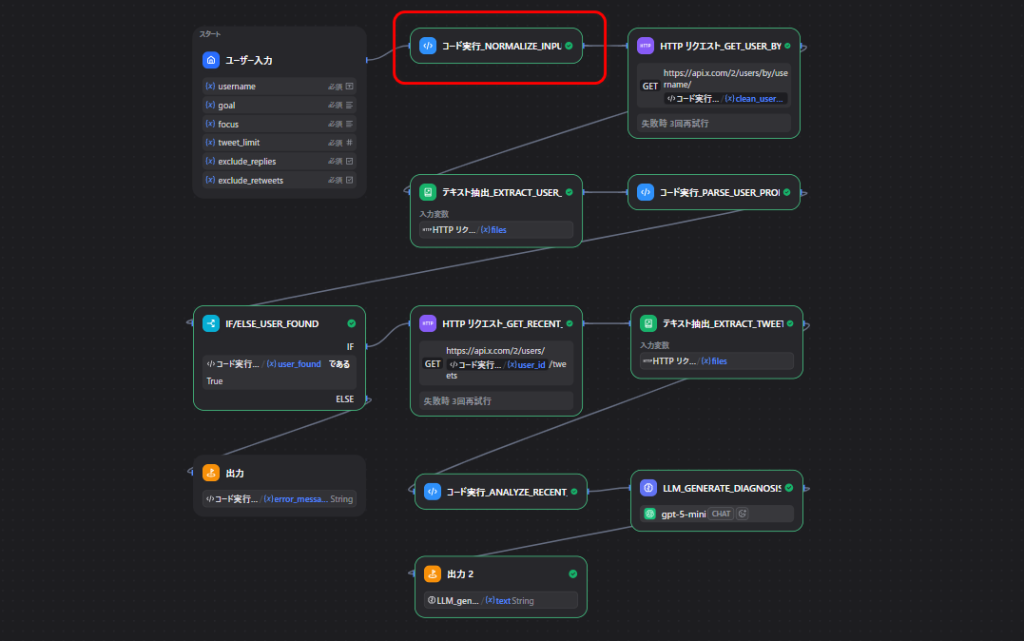
このノードでは、
@を消す- 取得件数を1〜10に収める
excludeパラメータを作る
という前処理をしています。
入力変数
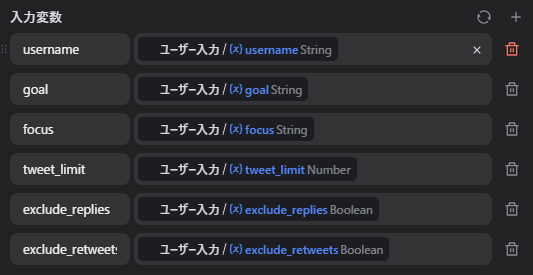
usernamegoalfocustweet_limitexclude_repliesexclude_retweets
出力変数
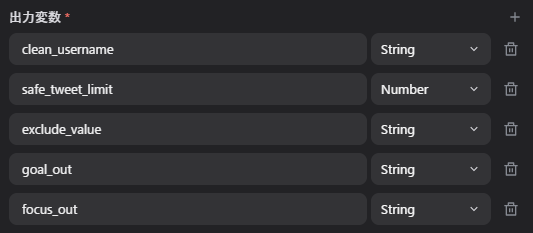
clean_usernamesafe_tweet_limitexclude_valuegoal_outfocus_out
コード
def main(username: str, goal: str, focus: str, tweet_limit: int, exclude_replies: bool, exclude_retweets: bool) -> dict:
clean = (username or "").strip().lstrip("@")
limit = max(1, min(int(tweet_limit or 10), 10))
excludes = []
if exclude_replies:
excludes.append("replies")
if exclude_retweets:
excludes.append("retweets")
return {
"clean_username": clean,
"safe_tweet_limit": limit,
"exclude_value": ",".join(excludes),
"goal_out": (goal or "認知拡大").strip(),
"focus_out": (focus or "投稿改善").strip(),
}ノード2: ユーザー情報を取得する
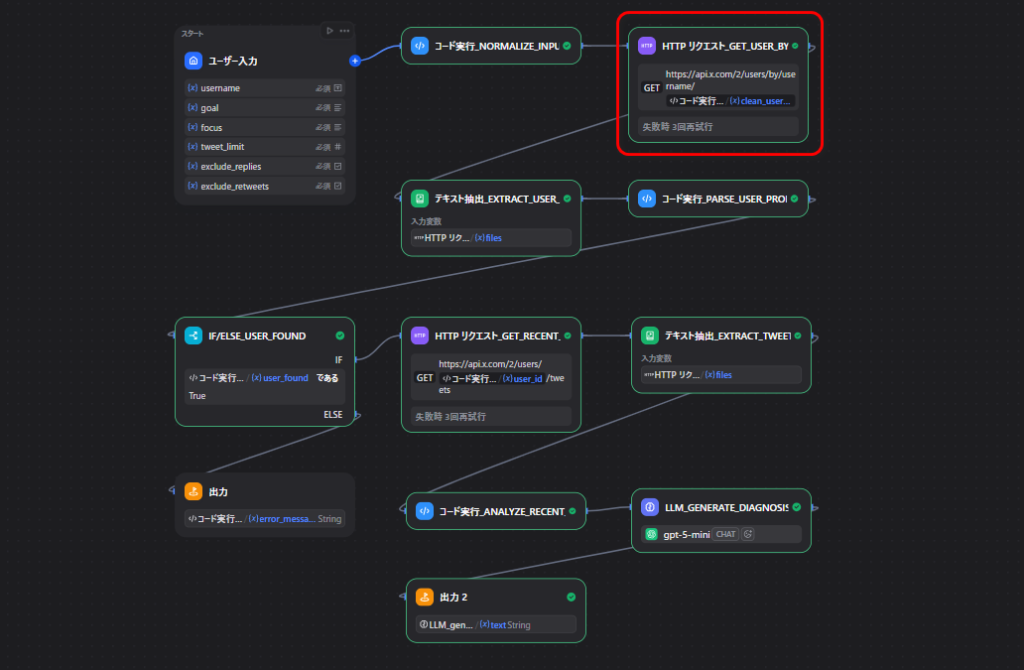
ここではX APIを使って、対象アカウントのプロフィール情報を取得します。
ここで使う X_BEARER_TOKEN は、前のセクションで準備したX APIの認証情報です。
HTTP Request の設定
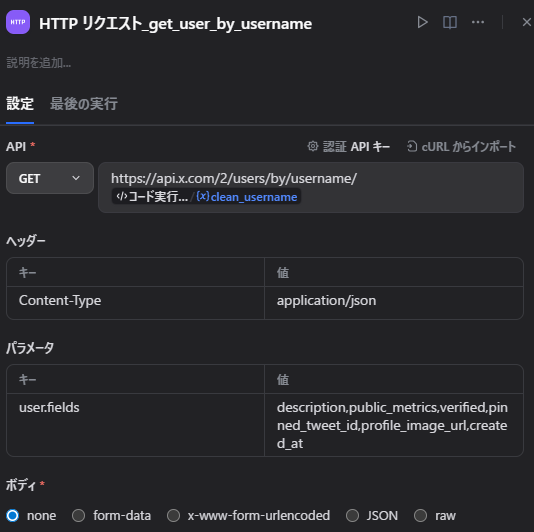
- Method:
GET - URL:
https://api.x.com/2/users/by/username/{{clean_username}}認証APIキー
- 認証タイプ: APIキー
- API認証タイプ: Bearer
{{X_BEARER_TOKEN}}Query
user.fields=description,public_metrics,verified,pinned_tweet_id,profile_image_url,created_atHeaders
Content-Type: application/jsonここで取得したいのは、主に次の情報です。
- 表示名
- ユーザー名
- 自己紹介
- フォロワー数
- フォロー数
- 投稿数
- 固定ポストID
- 認証状態
ノード3: ユーザー情報を読み取る
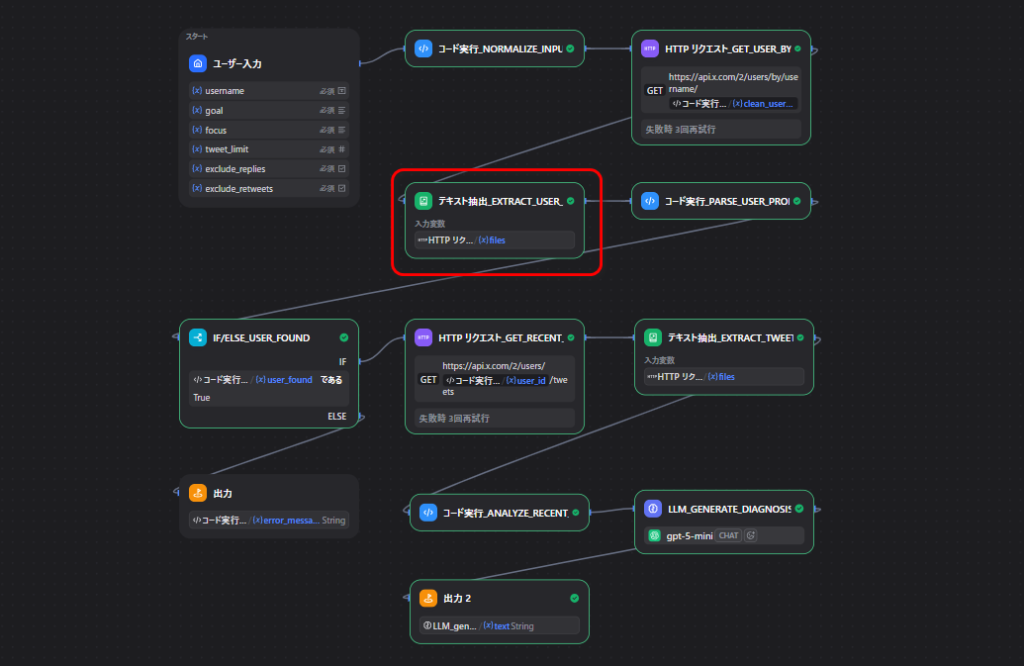
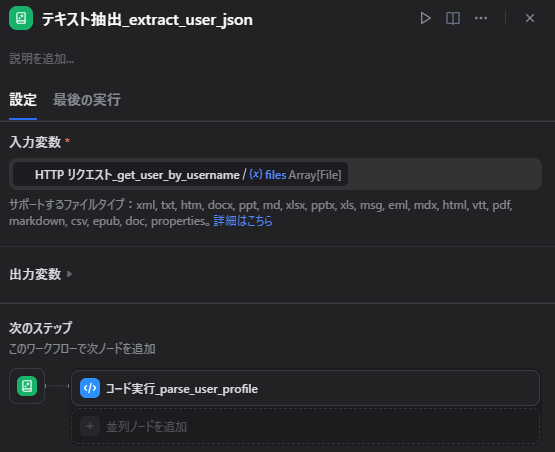
ここは少しハマりやすかったところです。
X APIのレスポンスが、Dify上では body ではなく files に入るケースがありました。
そのため、HTTP Request → Code ではなく、間に Document Extractor を挟んでいます。
このノードでやること
filesに入ったJSONを読み取る- 後続のCodeノードで扱えるように
textにする
入力
files = ユーザー情報を取得する.files
ノード4: プロフィールを整理する
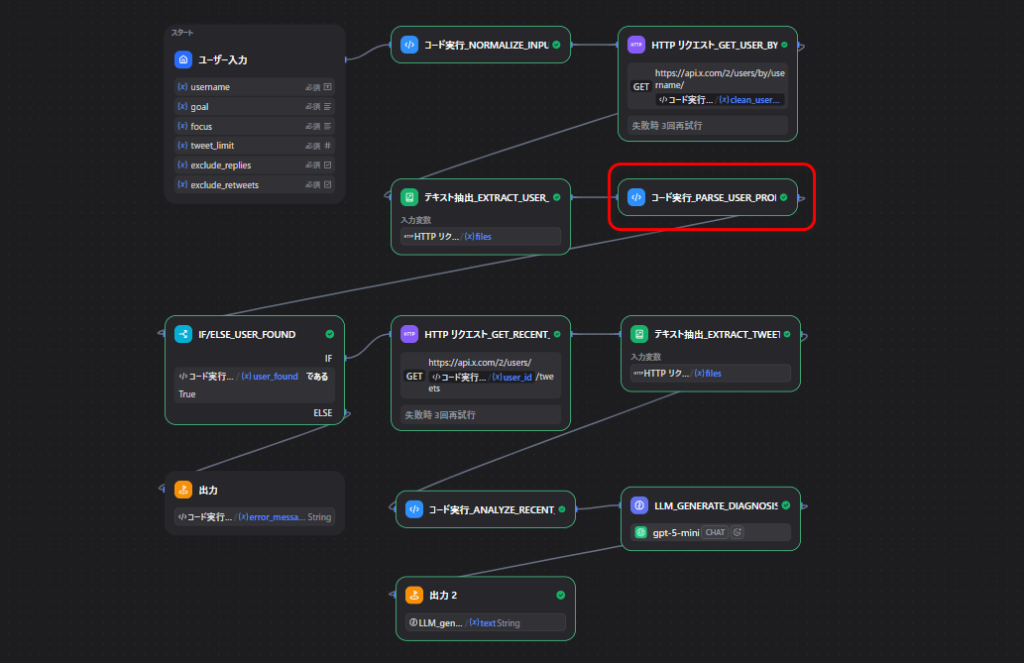
ここでは、Document Extractor から渡された text をJSONとして読み込み、使いやすい形に整えます。
入力変数

text
出力変数
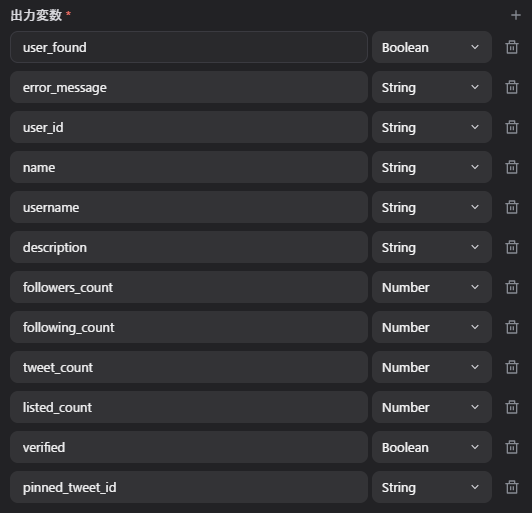
user_founderror_messageuser_idnameusernamedescriptionfollowers_countfollowing_counttweet_countlisted_countverifiedpinned_tweet_id
コード
def main(text) -> dict:
import json
def normalize_to_string(value) -> str:
if value is None:
return ""
if isinstance(value, str):
return value.strip()
if isinstance(value, list):
parts = []
for item in value:
if isinstance(item, str):
parts.append(item)
else:
parts.append(json.dumps(item, ensure_ascii=False))
return "\n".join(parts).strip()
if isinstance(value, dict):
return json.dumps(value, ensure_ascii=False).strip()
return str(value).strip()
raw = normalize_to_string(text)
if not raw:
return {
"user_found": False,
"error_message": "Document Extractorのtextが空です。",
"user_id": "",
"name": "",
"username": "",
"description": "",
"followers_count": 0,
"following_count": 0,
"tweet_count": 0,
"listed_count": 0,
"verified": False,
"pinned_tweet_id": ""
}
if raw.startswith("```"):
raw = raw.strip("`")
raw = raw.replace("json\n", "", 1).strip()
try:
payload = json.loads(raw)
except Exception as e:
return {
"user_found": False,
"error_message": f"JSON解析に失敗しました: {str(e)}",
"user_id": "",
"name": "",
"username": "",
"description": "",
"followers_count": 0,
"following_count": 0,
"tweet_count": 0,
"listed_count": 0,
"verified": False,
"pinned_tweet_id": ""
}
user = payload.get("data")
if not user:
return {
"user_found": False,
"error_message": "レスポンスにdataがありません。",
"user_id": "",
"name": "",
"username": "",
"description": "",
"followers_count": 0,
"following_count": 0,
"tweet_count": 0,
"listed_count": 0,
"verified": False,
"pinned_tweet_id": ""
}
metrics = user.get("public_metrics", {})
return {
"user_found": True,
"error_message": "",
"user_id": str(user.get("id", "")),
"name": str(user.get("name", "")),
"username": str(user.get("username", "")),
"description": str(user.get("description", "")),
"followers_count": int(metrics.get("followers_count", 0)),
"following_count": int(metrics.get("following_count", 0)),
"tweet_count": int(metrics.get("tweet_count", 0)),
"listed_count": int(metrics.get("listed_count", 0)),
"verified": bool(user.get("verified", False)),
"pinned_tweet_id": str(user.get("pinned_tweet_id", ""))
}ノード5: ユーザーが見つかったか確認する
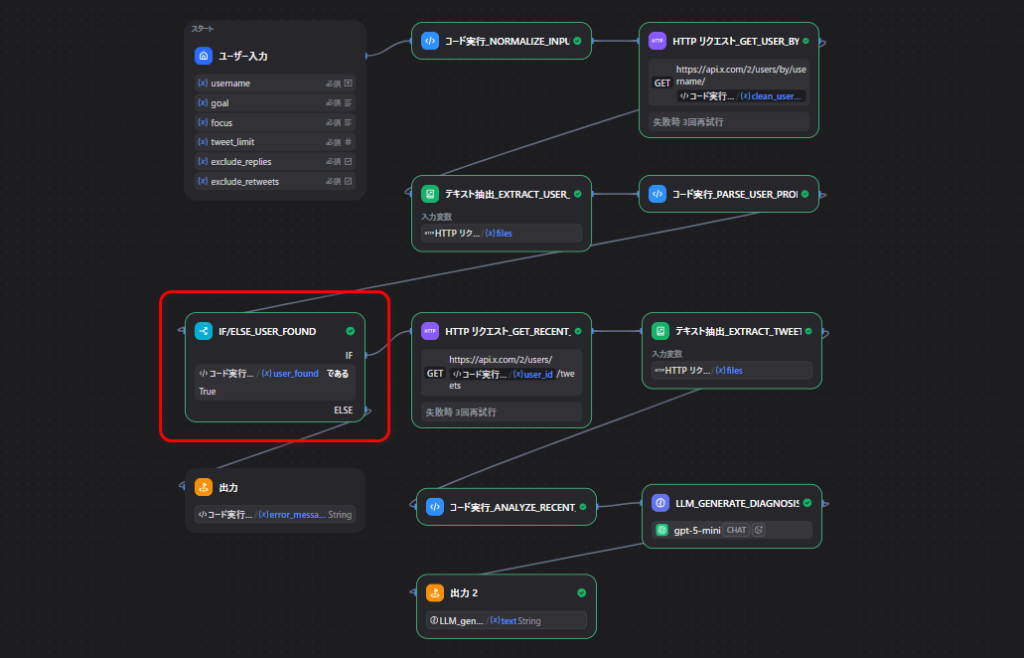
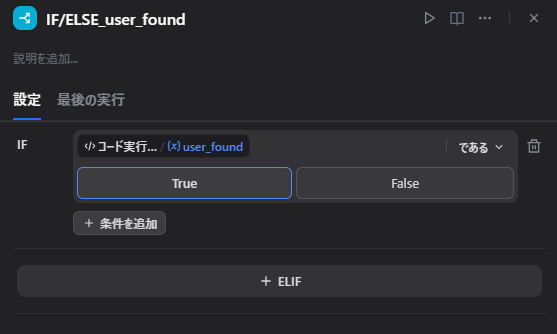
ここでは、user_found を見て分岐します。
trueなら次へ進むfalseならerror_messageを返して終了
地味ですが、初心者向けに作る場合は、こういうエラー分岐を入れておくとかなり親切です。
ノード6: 投稿一覧を取得する
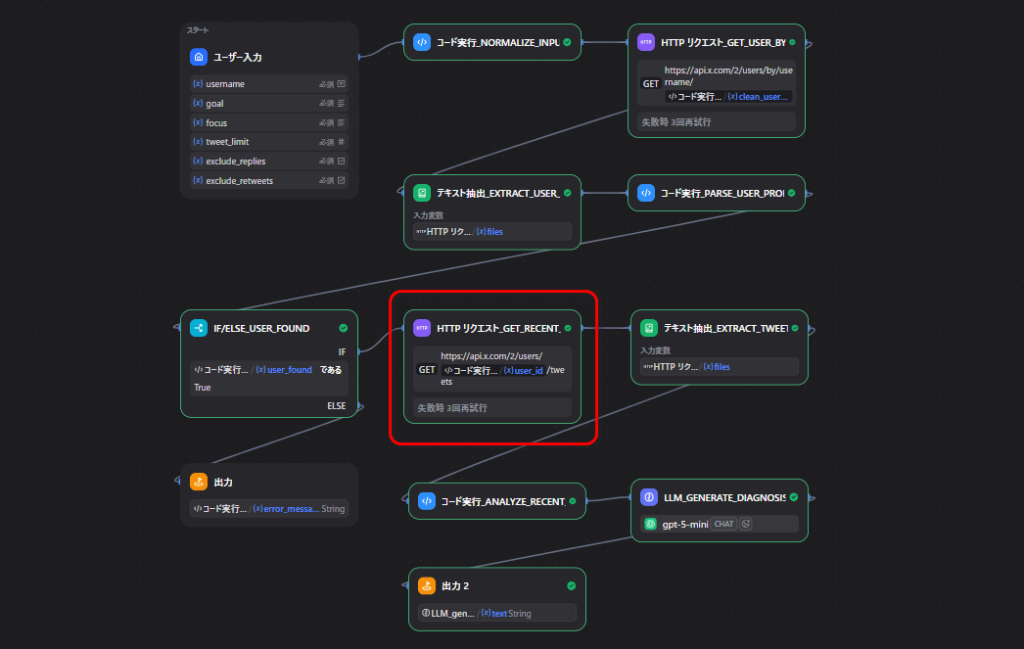
次に、対象アカウントの直近投稿を取得します。
HTTP Request の設定
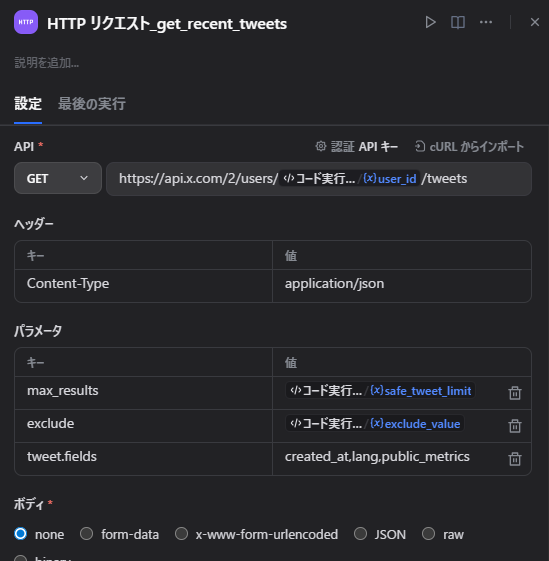
- Method:
GET - URL:
https://api.x.com/2/users/{{user_id}}/tweetsQuery
max_results={{safe_tweet_limit}}
tweet.fields=created_at,lang,public_metrics
exclude={{exclude_value}}Headers
Content-Type: application/json認証APIキー
- 認証タイプ: APIキー
- API認証タイプ: Bearer
{{X_BEARER_TOKEN}}今回は最小構成なので、まずは
- 投稿本文
- 投稿日時
- いいね数
- リポスト数
- 返信数
- 引用数
だけを使っています。
ノード7: 投稿一覧を読み取る
ここもユーザー情報のときと同じで、files に入るケースがあるため、Document Extractor を挟んでいます。
入力
files = 投稿一覧を取得する.files
ノード8: 投稿を分析する
ここでは、取得した投稿を整形して、平均値や反応上位投稿を作ります。
入力変数

text
出力変数
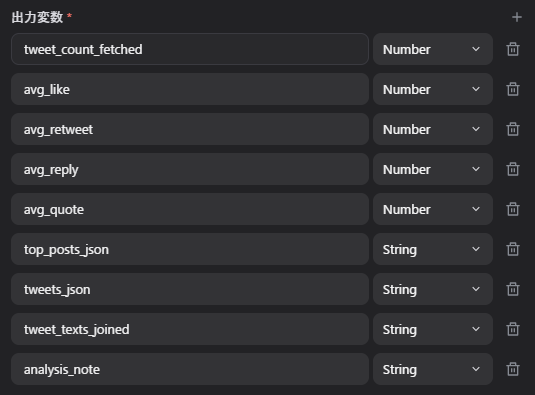
tweet_count_fetchedavg_likeavg_retweetavg_replyavg_quotetop_posts_jsontweets_jsontweet_texts_joinedanalysis_note
コード
def main(text) -> dict:
import json
from statistics import mean
def normalize_to_string(value) -> str:
if value is None:
return ""
if isinstance(value, str):
return value.strip()
if isinstance(value, list):
parts = []
for item in value:
if isinstance(item, str):
parts.append(item)
else:
parts.append(json.dumps(item, ensure_ascii=False))
return "\n".join(parts).strip()
if isinstance(value, dict):
return json.dumps(value, ensure_ascii=False).strip()
return str(value).strip()
raw = normalize_to_string(text)
if not raw:
return {
"tweet_count_fetched": 0,
"avg_like": 0,
"avg_retweet": 0,
"avg_reply": 0,
"avg_quote": 0,
"top_posts_json": "[]",
"tweets_json": "[]",
"tweet_texts_joined": "",
"analysis_note": "Document Extractorのtextが空です。"
}
if raw.startswith("```"):
raw = raw.strip("`")
raw = raw.replace("json\n", "", 1).strip()
try:
payload = json.loads(raw)
except Exception as e:
return {
"tweet_count_fetched": 0,
"avg_like": 0,
"avg_retweet": 0,
"avg_reply": 0,
"avg_quote": 0,
"top_posts_json": "[]",
"tweets_json": "[]",
"tweet_texts_joined": "",
"analysis_note": f"JSON解析に失敗しました: {str(e)}"
}
tweets = payload.get("data", [])
if not tweets:
return {
"tweet_count_fetched": 0,
"avg_like": 0,
"avg_retweet": 0,
"avg_reply": 0,
"avg_quote": 0,
"top_posts_json": "[]",
"tweets_json": "[]",
"tweet_texts_joined": "",
"analysis_note": "直近投稿が取得できませんでした。"
}
parsed = []
for t in tweets:
m = t.get("public_metrics", {})
parsed.append({
"id": str(t.get("id", "")),
"text": str(t.get("text", "")),
"created_at": str(t.get("created_at", "")),
"lang": str(t.get("lang", "")),
"like_count": int(m.get("like_count", 0)),
"retweet_count": int(m.get("retweet_count", 0)),
"reply_count": int(m.get("reply_count", 0)),
"quote_count": int(m.get("quote_count", 0)),
})
def score(x: dict) -> int:
return x["like_count"] + x["retweet_count"] * 2 + x["reply_count"] * 2 + x["quote_count"] * 2
top_posts = sorted(parsed, key=score, reverse=True)[:3]
return {
"tweet_count_fetched": len(parsed),
"avg_like": round(mean([x["like_count"] for x in parsed]), 2),
"avg_retweet": round(mean([x["retweet_count"] for x in parsed]), 2),
"avg_reply": round(mean([x["reply_count"] for x in parsed]), 2),
"avg_quote": round(mean([x["quote_count"] for x in parsed]), 2),
"top_posts_json": json.dumps(top_posts, ensure_ascii=False),
"tweets_json": json.dumps(parsed, ensure_ascii=False),
"tweet_texts_joined": "\n\n".join([x["text"] for x in parsed]),
"analysis_note": ""
}ノード9: 診断用データを整える
ここでは、スコア用に使う特徴量を整理しています。
入力変数
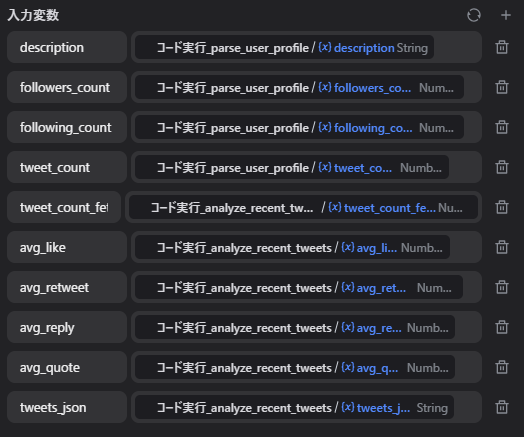
descriptionfollowers_countfollowing_counttweet_counttweet_count_fetchedavg_likeavg_retweetavg_replyavg_quotetweets_json
出力変数
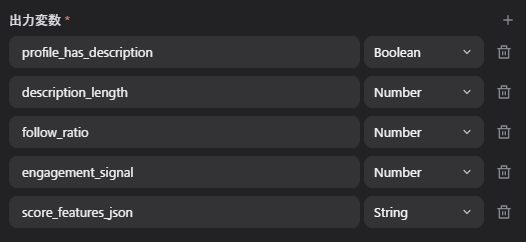
profile_has_descriptiondescription_lengthfollow_ratioengagement_signalscore_features_json
コード
def main(
description: str,
followers_count: int,
following_count: int,
tweet_count: int,
tweet_count_fetched: int,
avg_like: float,
avg_retweet: float,
avg_reply: float,
avg_quote: float,
tweets_json: str
) -> dict:
import json
desc = (description or "").strip()
following = following_count if following_count > 0 else 1
follow_ratio = round(followers_count / following, 2)
engagement_signal = round(avg_like + avg_retweet * 2 + avg_reply * 2 + avg_quote * 2, 2)
features = {
"profile_has_description": bool(desc),
"description_length": len(desc),
"followers_count": followers_count,
"following_count": following_count,
"follow_ratio": follow_ratio,
"tweet_count": tweet_count,
"tweet_count_fetched": tweet_count_fetched,
"avg_like": avg_like,
"avg_retweet": avg_retweet,
"avg_reply": avg_reply,
"avg_quote": avg_quote,
"engagement_signal": engagement_signal,
"tweets_json": tweets_json
}
return {
"profile_has_description": bool(desc),
"description_length": len(desc),
"follow_ratio": follow_ratio,
"engagement_signal": engagement_signal,
"score_features_json": json.dumps(features, ensure_ascii=False)
}ノード10: スコアを作る
ここではLLMに一度JSONだけ返させて100点満点のスコアを作ります。
入力
goal_outfocus_outnameusernamedescriptiontweets_jsontop_posts_jsonscore_features_json
プロンプト
あなたはXアカウント診断の評価者です。
与えられたデータだけを根拠に、100点満点の診断スコアをJSONで返してください。
採点項目は以下の5つで、各20点満点です。
- profile_clarity
- topic_consistency
- audience_fit
- engagement_potential
- improvement_readiness
ルール:
- 必ずJSONのみ返す
- コードブロックは使わない
- 各項目は0〜20の整数
- total_score は5項目の合計
- 各項目について reason を1文で返す
- データ不足なら reason に「暫定評価」と書く
入力データ:
発信目的: {{goal_out}}
見たい観点: {{focus_out}}
名前: {{name}}
ユーザー名: @{{username}}
自己紹介: {{description}}
特徴量:
{{score_features_json}}
反応上位投稿:
{{top_posts_json}}
投稿データ:
{{tweets_json}}
以下の形式のJSONだけ返してください。
{
"profile_clarity": {"score": 0, "reason": ""},
"topic_consistency": {"score": 0, "reason": ""},
"audience_fit": {"score": 0, "reason": ""},
"engagement_potential": {"score": 0, "reason": ""},
"improvement_readiness": {"score": 0, "reason": ""},
"total_score": 0
}このように一度JSONで出させると、後でレポートに使いやすくなります。
ノード11: 診断レポートを作る
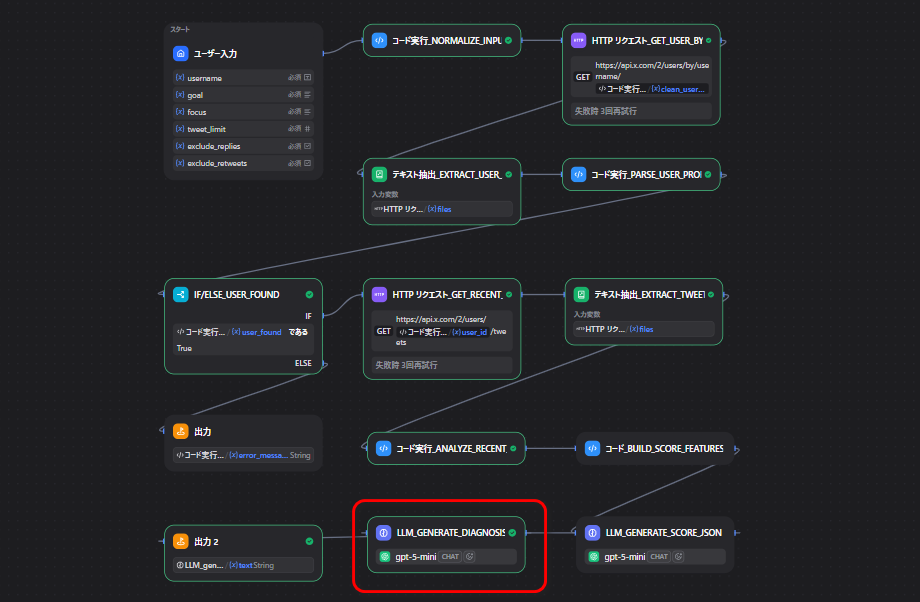
最後に、プロフィール情報、投稿分析結果、スコアを渡して診断レポートを作ります。
System Prompt
あなたはX運用診断の専門家です。
中小企業、個人事業主、発信初心者向けに、実務で使える改善提案を日本語で行ってください。
次のルールを必ず守ってください。
- 抽象論ではなく、すぐ試せる提案を書く
- 分からないことは断定しない
- 与えられたデータだけを根拠にする
- 厳しすぎる言い方は避けるが、改善点ははっきり伝える
- 出力は必ず指定された見出し順にする
- 投稿案はそのまま下書きに使える文章にするUser Prompt
以下のXアカウントを診断してください。
【診断条件】
発信目的: {{goal_out}}
見たい観点: {{focus_out}}
【プロフィール情報】
表示名: {{name}}
ユーザー名: @{{username}}
自己紹介: {{description}}
フォロワー数: {{followers_count}}
フォロー数: {{following_count}}
累計投稿数: {{tweet_count}}
認証済み: {{verified}}
【直近投稿の集計】
取得件数: {{tweet_count_fetched}}
平均いいね: {{avg_like}}
平均リポスト: {{avg_retweet}}
平均返信: {{avg_reply}}
平均引用: {{avg_quote}}
【反応上位投稿】
{{top_posts_json}}
【直近投稿データ】
{{tweets_json}}
【スコア情報】
{{score_json}}
【補足】
{{analysis_note}}
以下の形式を厳守して、Markdownで出力してください。
# Xアカウント簡易診断レポート
## 0. 総合スコア
- 100点満点中何点か
- 一言で今の状態
- 最優先の改善ポイント
## 1. 総評
- このアカウントが今どんな発信に見えるかを3〜5行でまとめる
## 2. 誰向けの発信か
- 想定読者
- 現状ズレて見える点
- より明確にした方がいい方向性
## 3. 直近投稿の傾向
- よく扱っているテーマ
- 反応が比較的取りやすそうな型
- 弱く見える型
## 4. 良い点
- 3つまで
## 5. 改善点
- 3つ
- それぞれ「問題」「改善案」「すぐできる行動」を書く
## 6. プロフィール改善案
- 表示名
- 自己紹介文
- 固定ポスト
それぞれ改善ポイントを書く
## 7. 次の投稿案3本
各案について以下の3項目を出す
- 狙い
- タイトル案
- 投稿本文ドラフト
## 8. 優先アクション
- 今日やること
- 今週やること
- 今月やること最後に返すもの
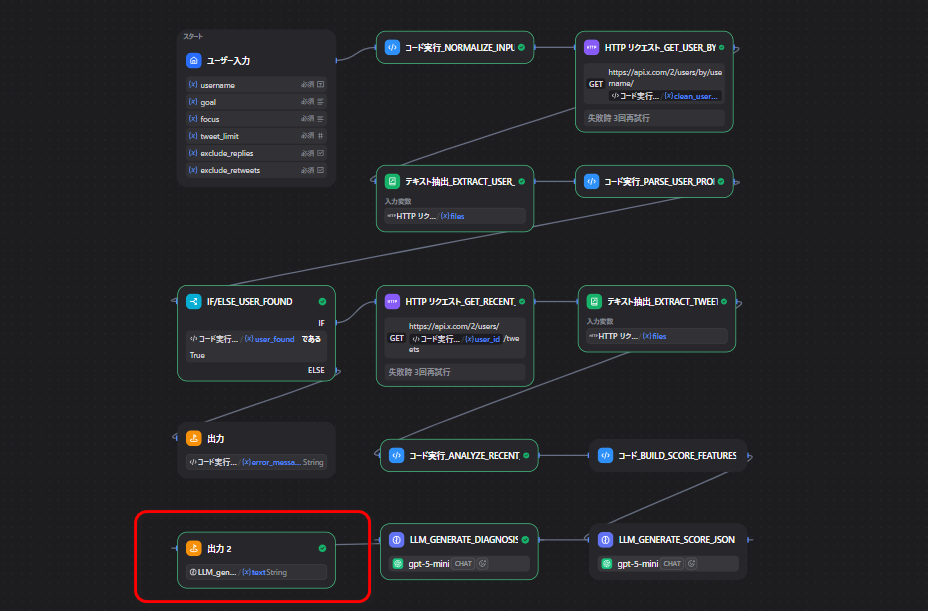

終了ノードでは最低限このあたりを返しておくと使いやすいです。
| 出力項目 | 説明 |
|---|---|
diagnosis_report |
診断レポート全文 |
username |
対象ユーザー名 |
followers_count |
フォロワー数 |
tweet_count_fetched |
取得投稿数 |
error_message |
エラー時の文言 |
ここまで作れれば十分な形
今回のMVPではあえて入れていないものもあります。
- 競合比較
- キーワード検索
- 自動投稿
- ダッシュボード
- 長期履歴の保存
- 画像分析
理由はシンプルで最初から広げすぎると動くところまで行きにくいからです。
まずは、
- 1アカウントを診断できる
- 最低限のスコアが出せる
- 改善案と投稿案を返せる
ここまでできれば、十分価値があります。
まとめ
今回はDifyでXアカウント簡易診断ツールを作る手順を全体構成ベースで紹介しました。
ポイントをまとめると、次の通りです。
- まずは最小構成で作るのがおすすめ
- ノード名を日本語にすると、自分でも流れを追いやすい
- X APIでユーザー情報と直近投稿を取得するだけでも十分診断できる
- 認証情報はコードに直接書かず、Dify側で管理する
- Difyでは、HTTP Requestの後にDocument Extractorが必要になることがある
- Codeノードでは、整形と平均値計算、特徴量作成を担当させると整理しやすい
- LLMは「スコア作成」と「診断レポート作成」を分けると扱いやすい
次回は今回かなりハマったポイントでもある
- bodyが空だった話
- filesにJSONが入っていた話
- Document Extractorを挟んだ理由
- listでエラーになった話
など、Dify×X APIでつまずきやすいところ を中心にまとめていきます。
もし、
- DifyでこういったAPI連携ツールを作りたい
- 自社向けに診断ツールや業務自動化ツールを作りたい
- まず何から整理すればいいか相談したい
という方がいれば、無料相談・お問い合わせからお気軽にご連絡ください。
小さなところからでも、一緒に整理していければと思います。
コメント